SQL SERVER INTERVIEW QUESTIONS
SQL SERVER INTERVIEW QUESTIONS
Friends,
In this post I am gonna add stuff related to Interview questions from SQL SERVER with answers. Hope this one will help you in cracking the Interviews on SQL SERVER.
- What are Constraints or Define Constraints ?
Generally we use Data Types to limit the kind of Data in a Column. For example, if we declare any column with data type INT then ONLY Integer data can be inserted into the column. Constraint will help us to limit the Values we are passing into a column or a table. In simple Constraints are nothing but Rules or Conditions applied on columns or tables to restrict the data.
- Different types of Constraints ?
There are THREE Types of Constraints.
- Domain
- Entity
- Referential
Domain has the following constraints types -
- Not Null
- Check
Entity has the following constraint types -
- Primary Key
- Unique Key
Referential has the following constraint types -
- Foreign Key
- What is the difference between Primary Key and Unique Key ?
Both the Primary Key(PK) and Unique Key(UK) are meant to provide Uniqueness to the Column on which they are defined. PFB the major differences between these two.
- By default PK defines Clustered Index in the column where as UK defines Non Clustered Index.
- PK doesn’t allow NULL Value where as UK allow ONLY ONE NULL.
- You can have only one PK per table where as UK can be more than one per table.
- PK can be used in Foreign Key relationships where as UK cannot be used.
- What is the difference between Delete and Truncate ?
Both Delete and Truncate commands are meant to remove rows from a table. There are many differences between these two and pfb the same.
- Truncate is Faster where as Delete is Slow process.
- Truncate doesn’t log where as Delete logs an entry for every record deleted in Transaction Log.
- We can rollback the Deleted data where as Truncated data cannot be rolled back.
- Truncate resets the Identity column where as Delete doesn’t.
- We can have WHERE Clause for delete where as for Truncate we cannot have WHERE Clause.
- Delete Activates TRIGGER where as TRUNCATE Cannot.
- Truncate is a DDL statement where as Delete is DML statement.
- What are Indexes or Indices ?
An Index in SQL is similar to the Index in a book. Index of a book makes the reader to go to the desired page or topic easily and Index in SQL helps in retrieving the data faster from database. An Index is a seperate physical data structure that enables queries to pull the data fast. Indexes or Indices are used to improve the performance of a query.
- Types of Indices in SQL ?
There are TWO types of Indices in SQL server.
- Clustered
- Non Clustered
- How many Clustered and Non Clustered Indexes can be defined for a table ?
Clustered – 1
Non Clustered – 999
- What is Transaction in SQL Server ?
Transaction groups a set of T-Sql Statements into a single execution unit. Each transaction begins with a specific task and ends when all the tasks in the group successfully complete. If any of the tasks fails, the transaction fails. Therefore, atransaction has only two results: success or failure. Incomplete steps result in the failure of the transaction.by programmers to group together read and write operations. In Simple Either FULL or NULL i.e either all the statements executes successfully or all the execution will be rolled back.
There are TWO forms of Transactions.
- Implicit – Specifies any Single Insert,Update or Delete statement as Transaction Unit. No need to specify Explicitly.
- Explicit – A group of T-Sql statements with the beginning and ending marked with Begin Transaction,Commit and RollBack. PFB an Example for Explicit transactions.
BEGIN TRANSACTION
Update Employee Set Emp_ID = 54321 where Emp_ID = 12345
If(@@Error <>0)
ROLLBACK
Update LEave_Details Set Emp_ID = 54321 where Emp_ID = 12345
If(@@Error <>0)
ROLLBACK
COMMIT
In the above example we are trying to update an EMPLOYEE ID from 12345 to 54321 in both the master table “Employee” and Transaction table “Leave_Details”. In this case either BOTH the tables will be updated with new EMPID or NONE.
- What is the Max size and Max number of columns for a row in a table ?
Size – 8060 Bytes
Columns – 1024
- What is Normalization and Explain different normal forms.
Database normalization is a process of data design and organization which applies to data structures based on rules that help building relational databases.
1. Organizing data to minimize redundancy.
2. Isolate data so that additions, deletions, and modifications of a field can be made in just one table and then propagated through the rest of the database via the defined relationships.
1NF: Eliminate Repeating Groups
Each set of related attributes should be in separate table, and give each table a primary key. Each field contains at most one value from its attribute domain.
2NF: Eliminate Redundant Data
1. Table must be in 1NF.
2. All fields are dependent on the whole of the primary key, or a relation is in 2NF if it is in 1NF and every non-key attribute is fully dependent on each candidate key of the relation. If an attribute depends on only part of a multi‐valued key, remove it to a separate table.
3NF: Eliminate Columns Not Dependent On Key
1. The table must be in 2NF.
2. Transitive dependencies must be eliminated. All attributes must rely only on the primary key. If attributes do not contribute to a description of the key, remove them to a separate table. All attributes must be directly dependent on the primary key.
BCNF: Boyce‐Codd Normal Form
for every one of its non-trivial functional dependencies X → Y, X is a superkey—that is, X is either a candidate key or a superset thereof. If there are non‐trivial dependencies between candidate key attributes, separate them out into distinct tables.
4NF: Isolate Independent Multiple Relationships
No table may contain two or more 1:n or n:m relationships that are not directly related.
For example, if you can have two phone numbers values and two email address values, then you should not have them in the same table.
5NF: Isolate Semantically Related Multiple Relationships
A 4NF table is said to be in the 5NF if and only if every join dependency in it is implied by the candidate keys. There may be practical constrains on information that justify separating logically related many‐to‐many relationships.
- What is Denormalization ?
For optimizing the performance of a database by adding redundant data or by grouping data is called de-normalization.
It is sometimes necessary because current DBMSs implement the relational model poorly.
In some cases, de-normalization helps cover up the inefficiencies inherent in relational database software. A relational normalized database imposes a heavy access load over physical storage of data even if it is well tuned for high performance.
A true relational DBMS would allow for a fully normalized database at the logical level, while providing physical storage of data that is tuned for high performance. De‐normalization is a technique to move from higher to lower normal forms of database modeling in order to speed up database access.
- Query to Pull ONLY duplicate records from table ?
There are many ways of doing the same and let me explain one here. We can acheive this by using the keywords GROUP and HAVING. The following query will extract duplicate records from a specific column of a particular table.
Select specificColumn
FROM particluarTable
GROUP BY specificColumn
HAVING COUNT(*) > 1
This will list all the records that are repeated in the column specified by “specificColumn” of a “particlarTable”.
- Types of Joins in SQL SERVER ?
There are 3 types of joins in Sql server.
- Inner Join
- Outer Join
- Cross Join
Outer join again classified into 3 types.
- Right Outer Join
- Left Outer Join
- Full Outer Join.
- What is Table Expressions in Sql Server ?
Table Expressions are subqueries that are used where a TABLE is Expected. There are TWO types of table Expressions.
- Derived tables
- Common Table Expressions.
Derived tables are table expression which appears in FROM Clause of a Query. PFB an example of the same.
select * from (Select Month(date) as Month,Year(Date) as Year from table1) AS Table2
In the above query the subquery in FROM Clause “(Select Month(date) as Month,Year(Date) as Year from table1) ” is called Derived Table.
- What is CTE or Common Table Expression ?
Common table expression (CTE) is a temporary named result set that you can reference within a
SELECT, INSERT, UPDATE, or DELETE statement. You can also use a CTE in a CREATE VIEW statement, as part of the view’s SELECT query. In addition, as of SQL Server 2008, you can add a CTE to the new MERGE statement. There are TWO types of CTEs in Sql Server -
- Recursive
- Non Recursive
- Difference between SmallDateTime and DateTime datatypes in Sql server ?
Both the data types are meant to specify date and time but these two has slight differences and pfb the same.
- DateTime occupies 4 Bytes of data where as SmallDateTime occupies only 2 Bytes.
- DateTime ranges from 01/01/1753 to 12/31/9999 where as SmallDateTime ranges from 01/01/1900 to 06/06/2079.
- What is SQL_VARIANT Datatype ?
The SQL_VARIANT data type can be used to store values of various data types at the same time, such as numeric values, strings, and date values. (The only types of values that cannot be stored are TIMESTAMP values.) Each value of an SQL_VARIANT column has two parts: the data value and the information that describes the value. (This information contains all properties of the actual data type of the value, such as length, scale, and precision.)
- What is Temporary table ?
A temporary table is a database object that is temporarily stored and managed by the database system. There are two types of Temp tables.
- Local
- Global
- What are the differences between Local Temp table and Global Temp table ?
Before going to the differences, let’s see the similarities.
- Both are stored in tempdb database.
- Both will be cleared once the connection,which is used to create the table, is closed.
- Both are meant to store data temporarily.
PFB the differences between these two.
- Local temp table is prefixed with # where as Global temp table with ##.
- Local temp table is valid for the current connection i.e the connection where it is created where as Global temp table is valid for all the connection.
- Local temp table cannot be shared between multiple users where as Global temp table can be shared.
- Whar are the differences between Temp table and Table variable ?
This is very routine question in interviews. Let’s see the major differences between these two.
- Table variables are Transaction neutral where as Temp tables are Transaction bound. For example if we declare and load data into a temp table and table variable in a transaction and if the transaction is ROLLEDBACK, still the table variable will have the data loaded where as Temp table will not be available as the transaction is rolled back.
- Temporary Tables are real tables so you can do things like CREATE INDEXes, etc. If you have large amounts of data for which accessing by index will be faster then temporary tables are a good option.
- Table variables don’t participate in transactions, logging or locking. This means they’re faster as they don’t require the overhead.
- You can create a temp table using SELECT INTO, which can be quicker to write (good for ad-hoc querying) and may allow you to deal with changing datatypes over time, since you don’t need to define your temp table structure upfront.
- What is the difference between Char,Varchar and nVarchar datatypes ?
char[(n)] - Fixed-length non-Unicode character data with length of n bytes. n must be a value from 1 through 8,000. Storage size is n bytes. The SQL-92 synonym for char is character.
varchar[(n)] - Variable-length non-Unicode character data with length of n bytes. n must be a value from 1 through 8,000. Storage size is the actual length in bytes of the data entered, not n bytes. The data entered can be 0 characters in length. The SQL-92 synonyms for varchar are char varying or character varying.
nvarchar(n) - Variable-length Unicode character data of n characters. n must be a value from 1 through 4,000. Storage size, in bytes, is two times the number of characters entered. The data entered can be 0 characters in length. The SQL-92 synonyms for nvarchar are national char varying and national character varying.
- What is the difference between STUFF and REPLACE functions in Sql server ?
The Stuff function is used to replace characters in a string. This function can be used to delete a certain length of the string and replace it with a new string.
Syntax – STUFF (string_expression, start, length, replacement_characters)
Ex - SELECT STUFF(‘I am a bad boy’,8,3,’good’)
Output – “I am a good boy”
REPLACE function replaces all occurrences of the second given string expression in the first string expression with a third expression.
Syntax - REPLACE (String, StringToReplace, StringTobeReplaced)
Ex – REPLACE(“Roopesh”,”pe”,”ep”)
Output – “Rooepsh” – You can see PE is replaced with EP in the output.
Sometimes we need to know about the data which is being inserted/deleted by triggers in database. Whenever a trigger fires in response to the INSERT, DELETE, or UPDATE statement, two special tables are created. These are the inserted and the deleted tables. They are also referred to as themagic tables. These are the conceptual tables and are similar in structure to the table on which trigger is defined (the trigger table).
The inserted table contains a copy of all records that are inserted in the trigger table.
The deleted table contains all records that have been deleted from deleted from the trigger table.
Whenever any updation takes place, the trigger uses both the inserted and deleted tables.
- Explain about RANK,ROW_NUMBER and DENSE_RANK in Sql server ?
Found a very interesting explanation for the same in the url
Click Here . PFB the content of the same here.
Lets take 1 simple example to understand the difference between 3.
First lets create some sample data :
– create table
CREATE TABLE Salaries
(
Names VARCHAR(1),
SalarY INT
)
GO
– insert data
INSERT INTO Salaries SELECT
‘A’,5000 UNION ALL SELECT
‘B’,5000 UNION ALL SELECT
‘C’,3000 UNION ALL SELECT
‘D’,4000 UNION ALL SELECT
‘E’,6000 UNION ALL SELECT
‘F’,10000
GO
– Test the data
SELECT Names, Salary
FROM Salaries
Now lets query the table to get the salaries of all employees with their salary in descending order.
For that I’ll write a query like this :
SELECT names
, salary
,row_number () OVER (ORDER BY salary DESC) as ROW_NUMBER
,rank () OVER (ORDER BY salary DESC) as RANK
,dense_rank () OVER (ORDER BY salary DESC) as DENSE_RANK
FROM salaries
>>Output
| NAMES | SALARY | ROW_NUMBER | RANK | DENSE_RANK |
| F | 10000 | 1 | 1 | 1 |
| E | 6000 | 2 | 2 | 2 |
| A | 5000 | 3 | 3 | 3 |
| B | 5000 | 4 | 3 | 3 |
| D | 4000 | 5 | 5 | 4 |
| C | 3000 | 6 | 6 | 5 |
Interesting Names in the result are employee A, B and D. Row_number assign different number to them. Rank and Dense_rank both assign same rank to A and B. But interesting thing is what RANK and DENSE_RANK assign to next row? Rank assign 5 to the next row, while dense_rank assign 4.
The numbers returned by the DENSE_RANK function do not have gaps and always have consecutive ranks. The RANK function does not always return consecutive integers. The ORDER BY clause determines the sequence in which the rows are assigned their unique ROW_NUMBER within a specified partition.
So question is which one to use?
Its all depends on your requirement and business rule you are following.
1. Row_number to be used only when you just want to have serial number on result set. It is not as intelligent as RANK and DENSE_RANK.
2. Choice between RANK and DENSE_RANK depends on business rule you are following. Rank leaves the gaps between number when it sees common values in 2 or more rows. DENSE_RANK don’t leave any gaps between ranks.
So while assigning the next rank to the row RANK will consider the total count of rows before that row and DESNE_RANK will just give next rank according to the value.
So If you are selecting employee’s rank according to their salaries you should be using DENSE_RANK and if you are ranking students according to there marks you should be using RANK(Though it is not mandatory, depends on your requirement.)
- What are the differences between WHERE and HAVING clauses in SQl Server ?
PFB the major differences between WHERE and HAVING Clauses ..
1.Where Clause can be used other than Select statement also where as Having is used only with the SELECT statement.
2.Where applies to each and single row and Having applies to summarized rows (summarized with GROUP BY).
3.In Where clause the data that fetched from memory according to condition and In having the completed data firstly fetched and then separated according to condition.
4.Where is used before GROUP BY clause and HAVING clause is used to impose condition on GROUP Function and is used after GROUP BY clause in the query.
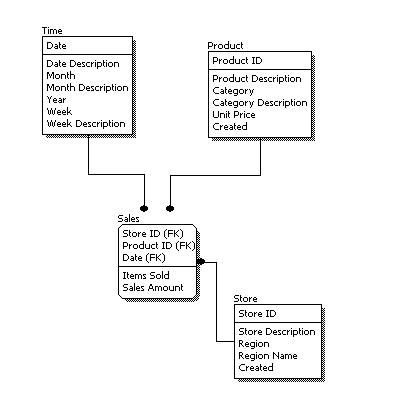
- Explain Physical Data Model or PDM ?
Physical data model represents how the model will be built in the database. A physical database model shows all table structures, including column name, column data type, column constraints, primary key, foreign key, and relationships between tables. Features of a physical data model include:
- Specification all tables and columns.
- Foreign keys are used to identify relationships between tables.
- Specying Data types.
EG -
- Explain Logical Data Model ?
A logical data model describes the data in as much detail as possible, without regard to how they will be physical implemented in the database. Features of a logical data model include:
- Includes all entities and relationships among them.
- All attributes for each entity are specified.
- The primary key for each entity is specified.
- Foreign keys (keys identifying the relationship between different entities) are specified.
- Normalization occurs at this level.
- Explain Conceptual Data Model ?
A conceptual data model identifies the highest-level relationships between the different entities. Features of conceptual data model include:
- Includes the important entities and the relationships among them.
- No attribute is specified.
- No primary key is specified.
Log Shipping is a basic level SQL Server high-availability technology that is part of SQL Server. It is an automated backup/restore process that allows you to create another copy of your database for failover.
Log shipping involves copying a database backup and subsequent transaction log backups from the primary (source) server and restoring the database and transaction log backups on one or more secondary (Stand By / Destination) servers. The Target Database is in a standby or no-recovery mode on the secondary server(s) which allows subsequent transaction logs to be backed up on the primary and shipped (or copied) to the secondary servers and then applied (restored) there.
- What are the advantages of database normalization ?
Benefits of normalizing the database are
- No need to restructure existing tables for new data.
- Reducing repetitive entries.
- Reducing required storage space
- Increased speed and flexibility of queries.
- What are Linked Servers ?
Linked servers are configured to enable the Database Engine to execute a Transact-SQL statement that includes tables in another instance of SQL Server, or another database product such as Oracle. Many types OLE DB data sources can be configured as linked servers, including Microsoft Access and Excel. Linked servers offer the following advantages:
- The ability to access data from outside of SQL Server.
- The ability to issue distributed queries, updates, commands, and transactions on heterogeneous data sources across the enterprise.
- The ability to address diverse data sources similarly.
- Can connect to MOLAP databases too.
- What is the Difference between the functions COUNT and COUNT_BIG ?
Both Count and Count_Big functions are used to count the number of rows in a table and the only difference is what it returns.
- Count returns INT datatype value where as Count_Big returns BIGINT datatype value.
- Count is used if the rows in a table are less where as Count_Big will be used when the numbenr of records are in millions or above.
Syntax -
- Count – Select count(*) from tablename
- Count_Big – Select Count_Big(*) from tablename
- How to insert values EXPLICITLY to an Identity Column ?
This has become a common question these days in interviews. Actually we cannot Pass values to Identity column and you will get the following error message when you try to pass value.
Msg 544, Level 16, State 1, Line 3
Cannot insert explicit value for identity column in table 'tablename' when IDENTITY_INSERT is set to OFF.
To pass an external value we can use the property IDENTITY_INSERT. PFB the sysntax of the same.
SET IDENTITY_INSERT <tablename> ON;
Write your Insert statement here by passing external values to the IDENTITY column.
Once the data is inserted then remember to SET the property to OFF.
- How to RENAME a table and column in SQL ?
We can rename a table or a column in SQL using the System stored procedure SP_RENAME. PFB the sample queries.
Table - EXEC sp_rename @objname = department, @newname = subdivision
Column - EXEC sp_rename @objname = ‘sales.order_no’ , @newname = ordernumber
- How to rename a database ?
To rename a database please use the below syntax.
USE master;
GO
ALTER DATABASE databasename
Modify Name = newname ;
GO
- What is the use the UPDATE_STATISTICS command ?
UPDATE_STATISTICS updates the indexes on the tables when there is large processing of data. If we do a large amount of deletions any modification or Bulk Copy into the tables, we need to basically update the indexes to take these changes into account.
- How to read the last record from a table with Identity Column ?
We can get the same using couple of ways and PFB the same.
First -
SELECT *
FROM TABLE
WHERE ID = IDENT_CURRENT(‘TABLE’)
Second -
SELECT *
FROM TABLE
WHERE ID = (SELECT MAX(ID) FROM TABLE)
Third -
select top 1 * from TABLE_NAME order by ID desc
A worktable is a temporary table used internally by SQL Server to process the intermediate results of a query. Worktables are created in the tempdb database and are dropped automatically after query execution. Thease table cannot be seen as these are created while a query executing and dropped immediately after the execution of the query.
A table with NO CLUSTERED INDEXES is called as HEAP table. The data rows of a heap table are not stored in any particular order or linked to the adjacent pages in the table. This unorganized structure of the heap table usually increases the overhead of accessing a large heap table, when compared to accessing a large nonheap table (a table with clustered index). So, prefer not to go with HEAP tables ..

If you define a NON CLUSTERED index on a table then the index row of a nonclustered index contains a pointer to the corresponding data row of the table. This pointer is called a row locator. The value of the row locator depends on whether the data pages are stored in a heap or are clustered. For a nonclustered index, the row locator is a pointer to the data row. For a table with a clustered index, the row locator is the clustered index key value.
A covering index is a nonclustered index built upon all the columns required to satisfy a SQL query without going to the base table. If a query encounters an index and does not need to refer to the underlying data table at all, then the index can be considered a covering index. For Example
Select col1,col2 from table
where col3 = Value
group by col4
order by col5
Now if you create a clustered index for all the columns used in Select statement then the SQL doesn’t need to go to base tables as everything required are available in index pages.
A database view in SQL Server is like a virtual table that represents the output of a SELECT statement. A view is created using the CREATE VIEW statement, and it can be queried exactly like a table. In general, a view doesn’t store any data—only the SELECT statement associated with it. Every time a view is queried, it further queries the underlying tables by executing its associated SELECT statement.
A database view can be materialized on the disk by creating a unique clustered index on the view. Such a view is referred to as an indexed view. After a unique clustered index is created on the view, the view’s result set is materialized immediately and persisted in physical storage in the database, saving the overhead of performing costly operations during query execution. After the view is materialized, multiple nonclustered indexes can be created on the indexed view.
- What is Bookmark Lookup ?
When a SQL query requests a small number of rows, the optimizer can use the nonclustered index, if available, on the column(s) in the WHERE clause to retrieve the data. If the query refers to columns that are not part of the nonclustered index used to retrieve the data, then navigation is required from the index row to the corresponding data row in the table to access these columns.This operation is called a bookmark lookup.